
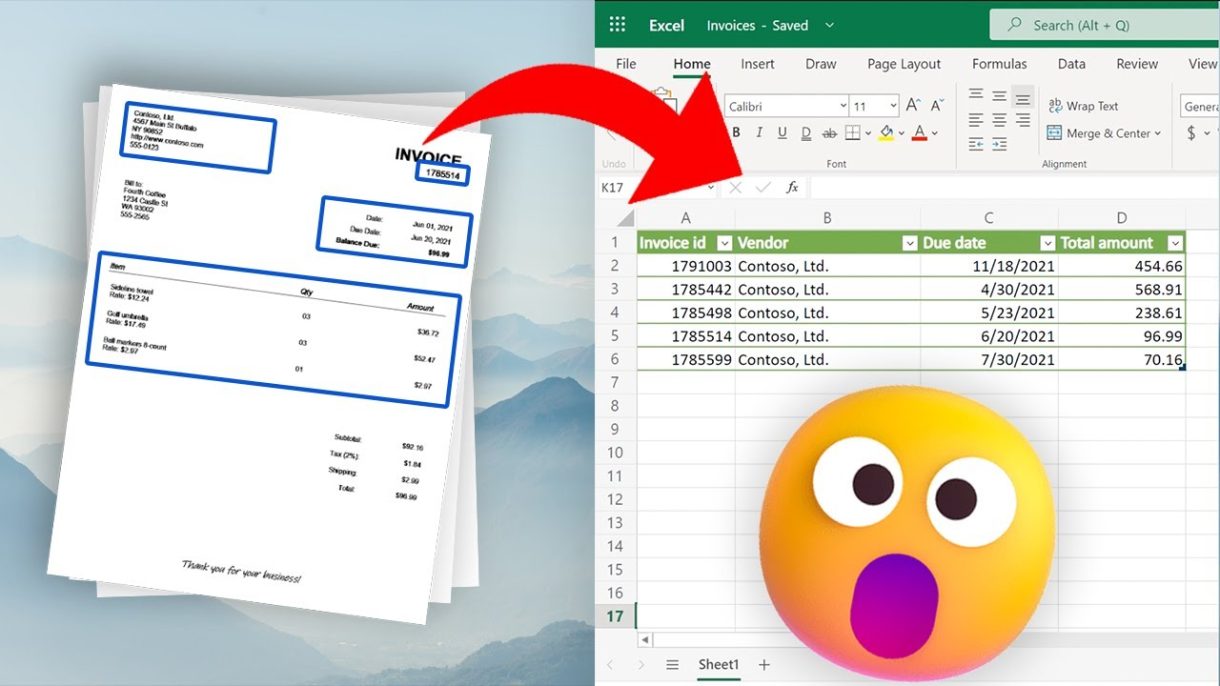

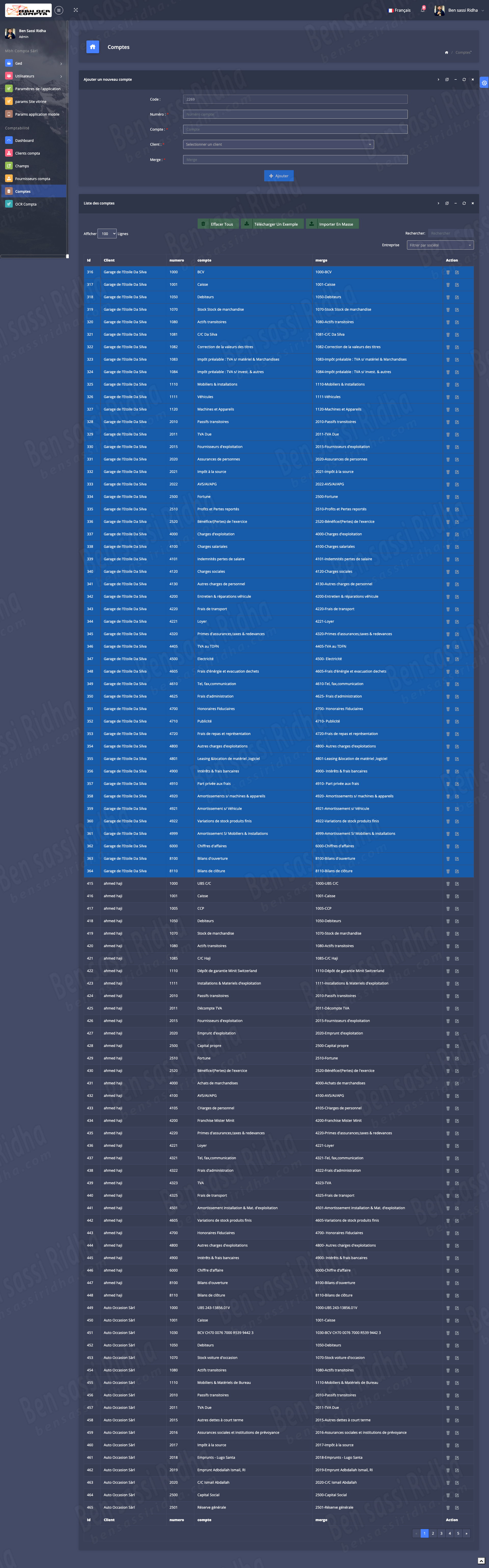
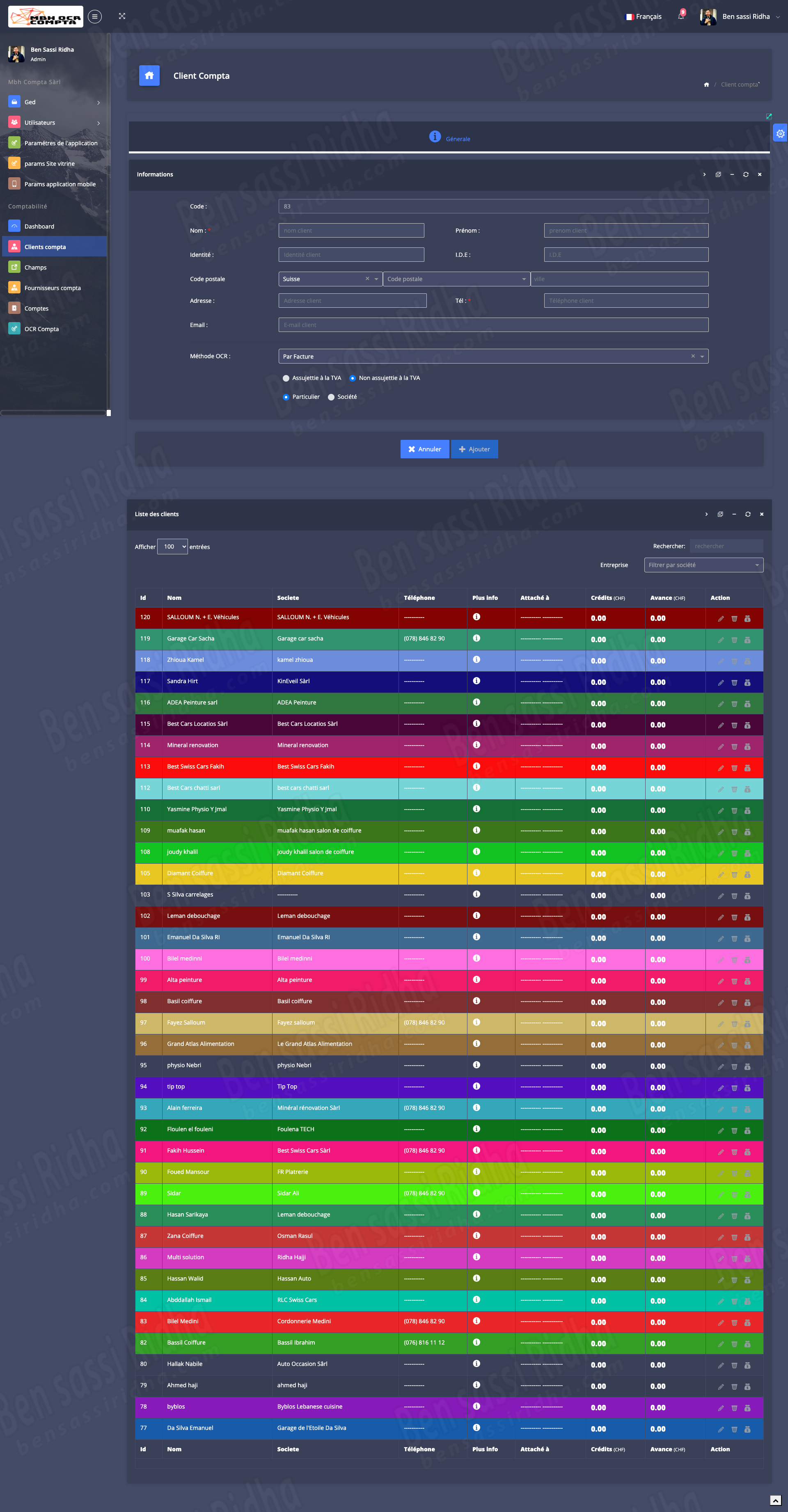
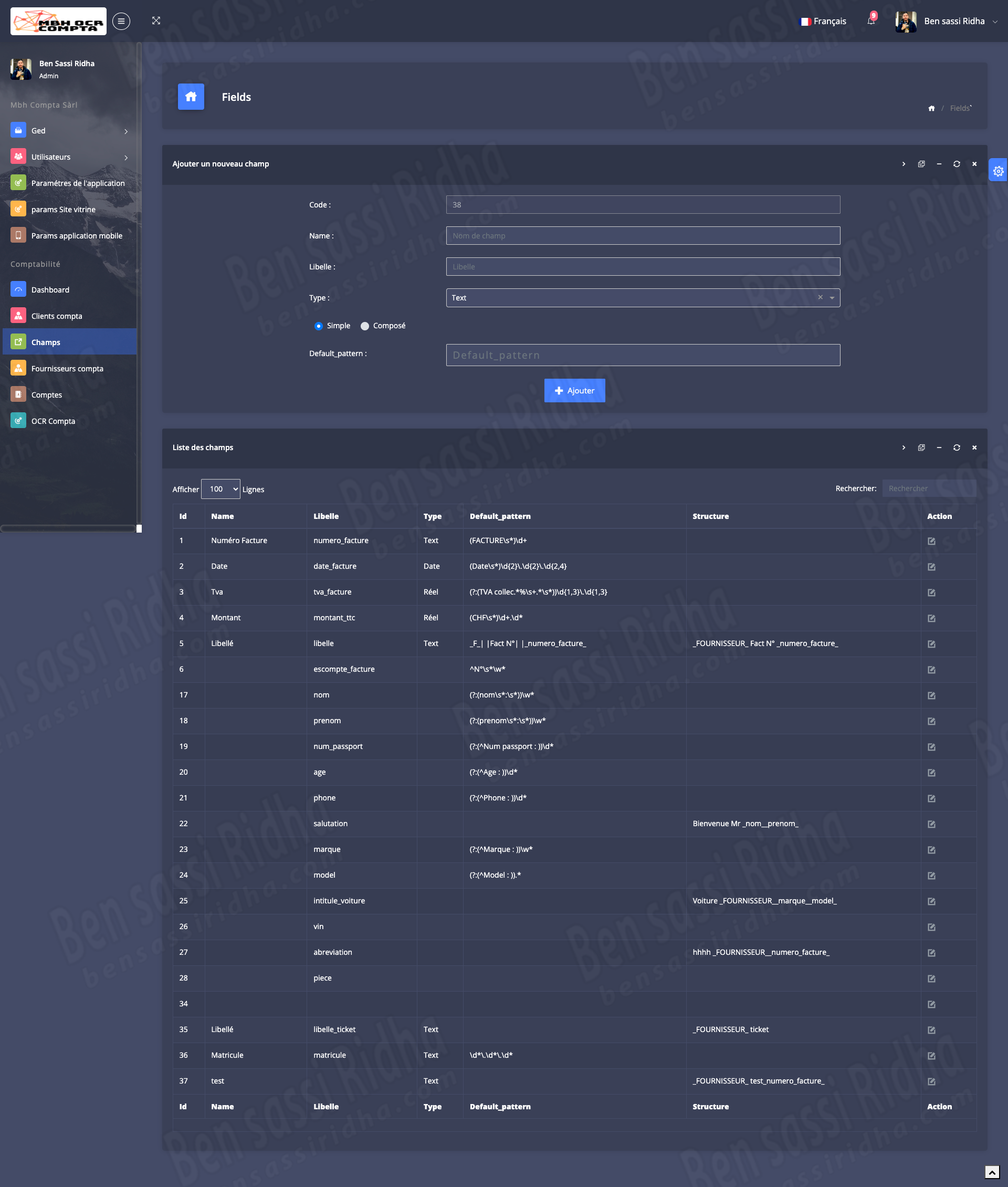
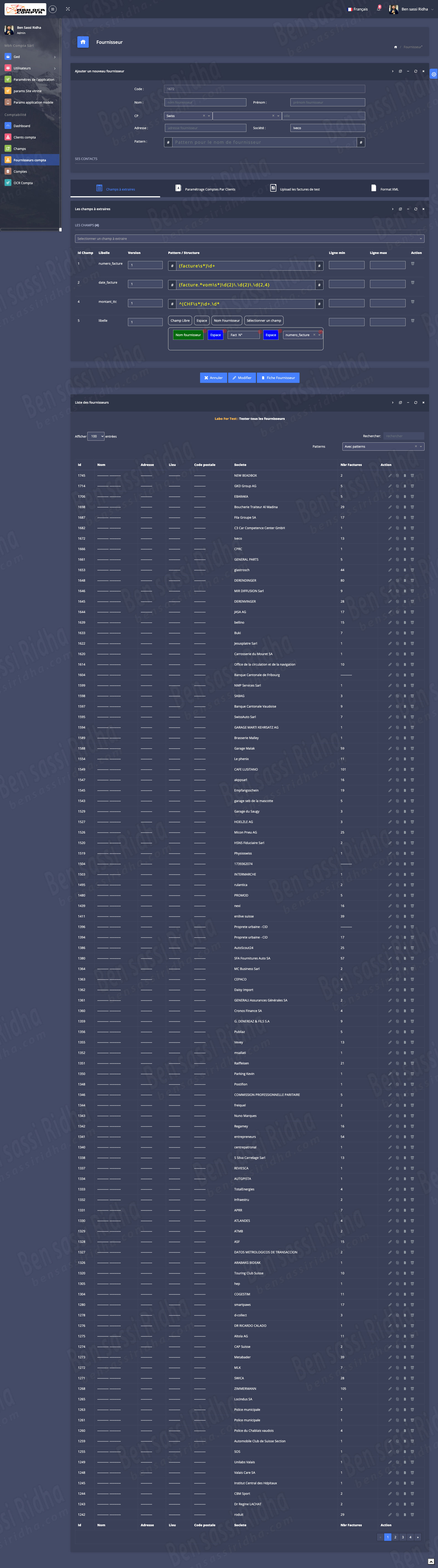
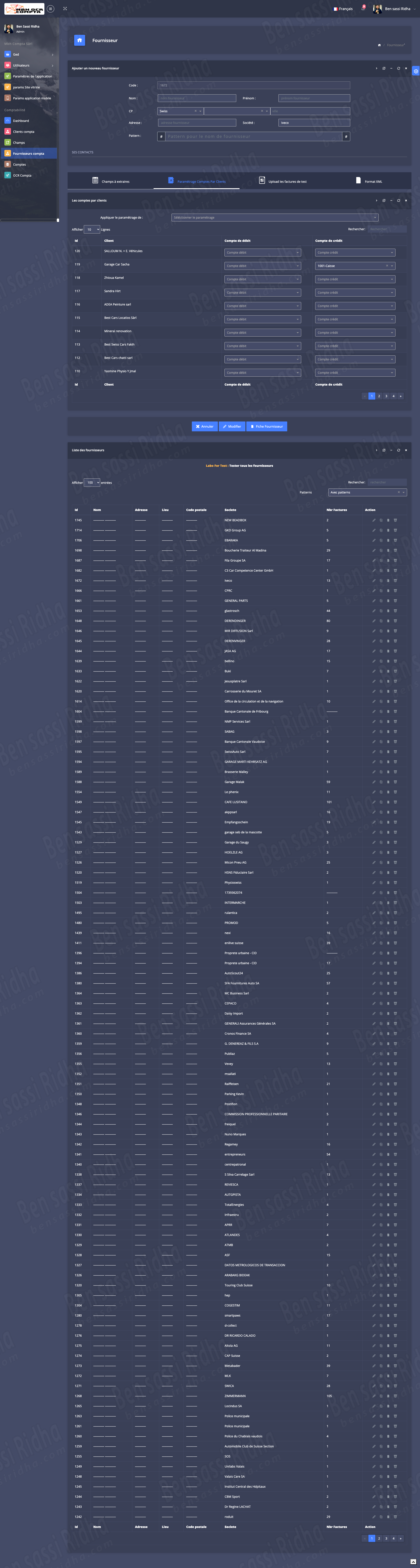
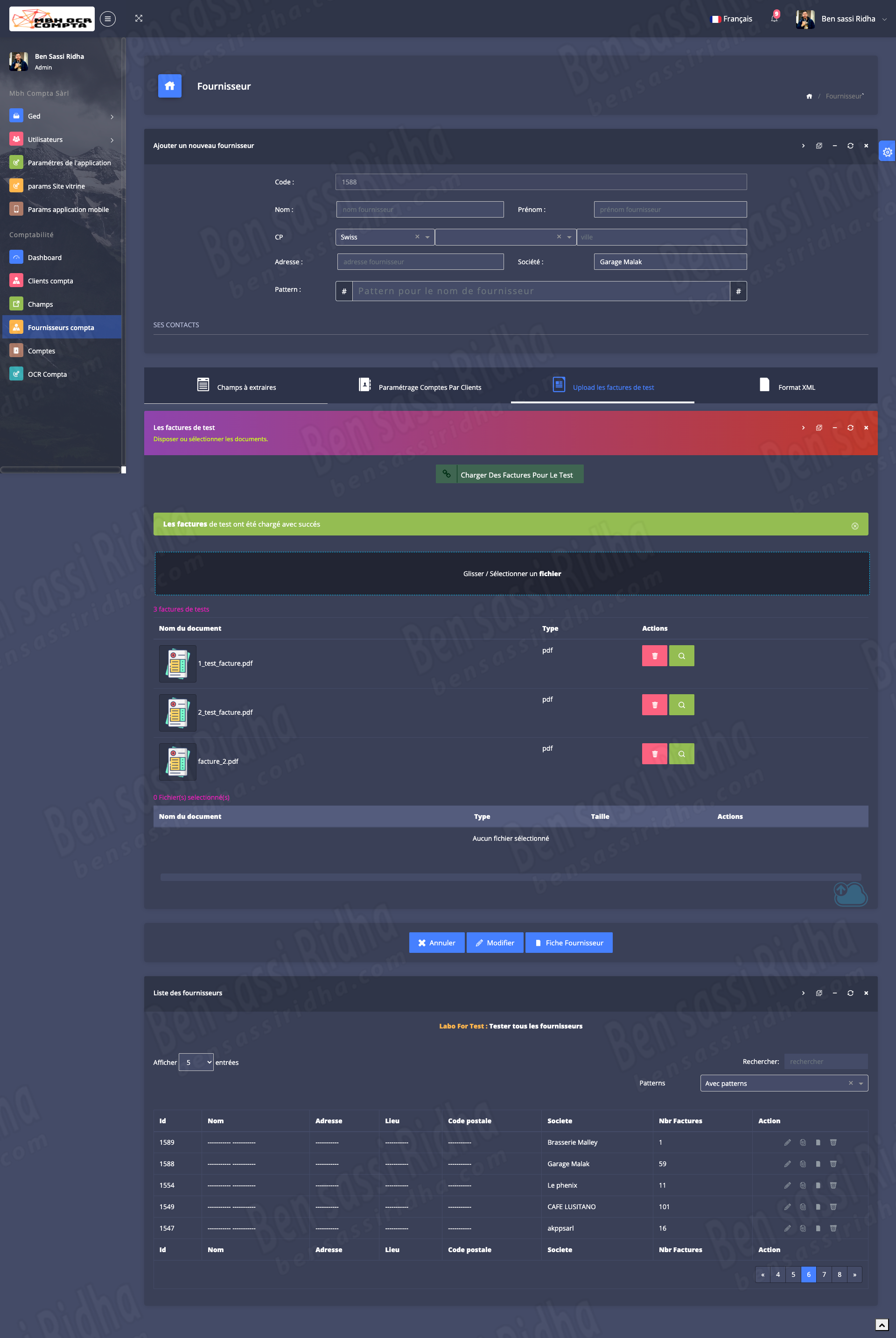
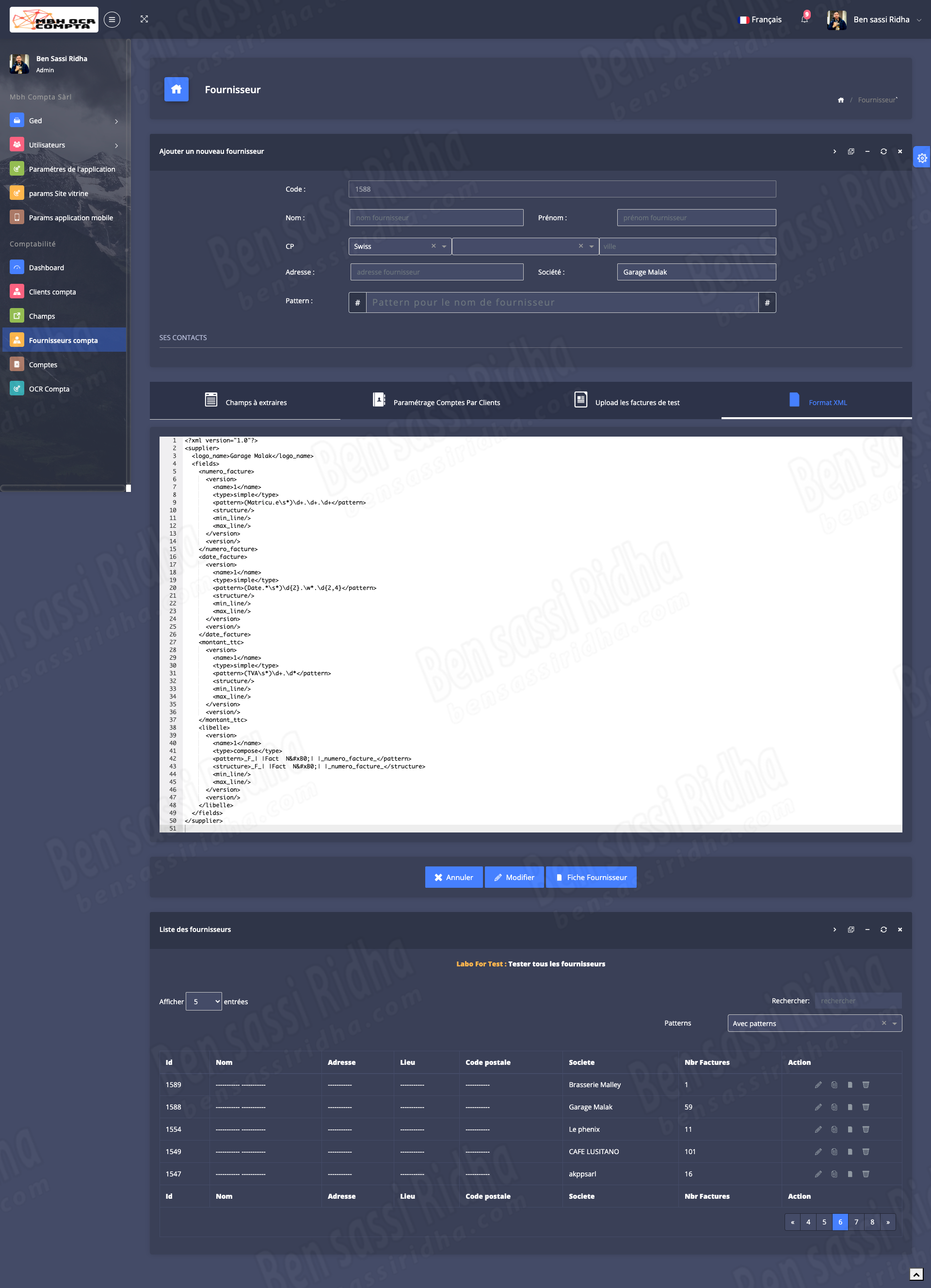
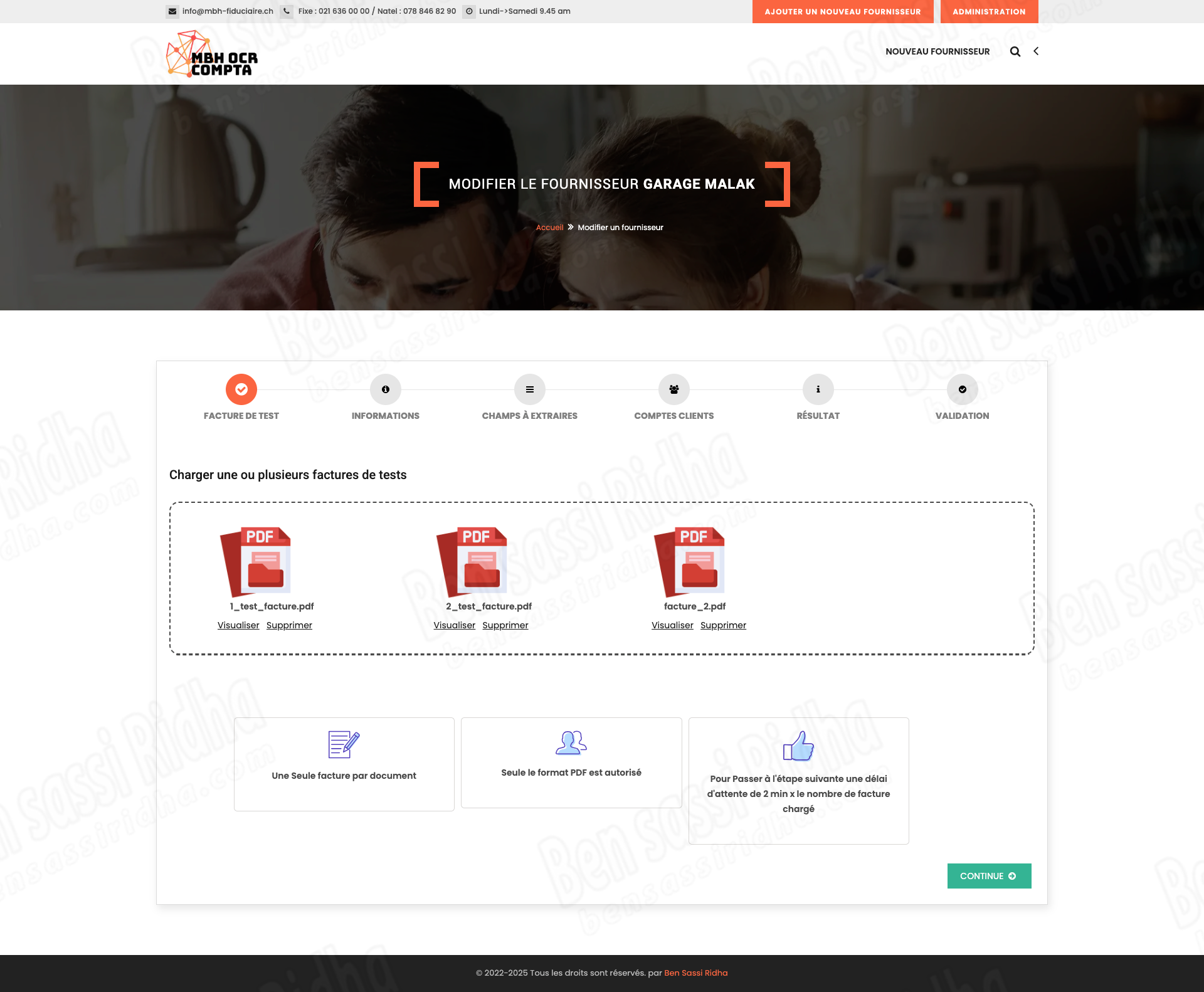
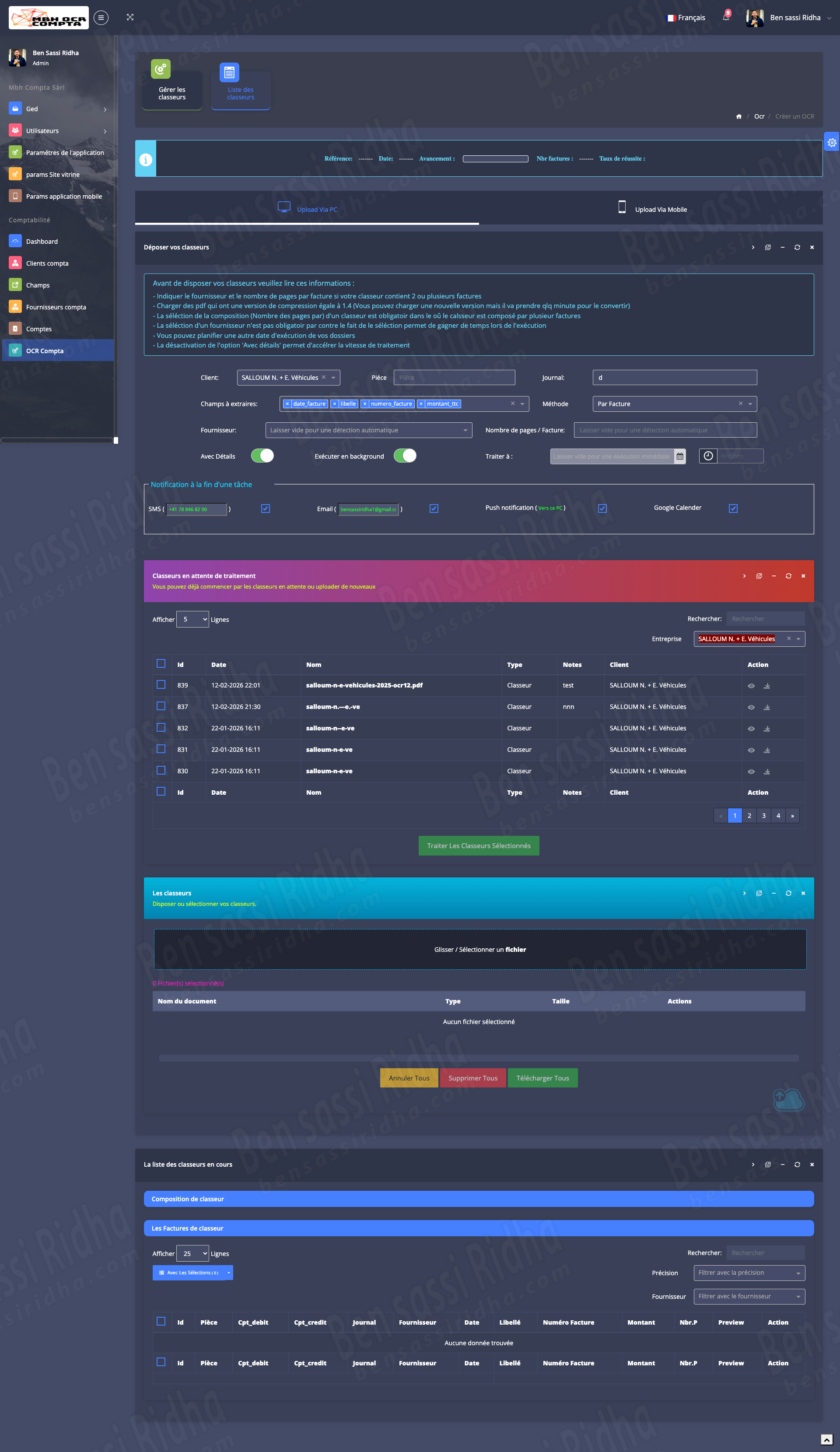
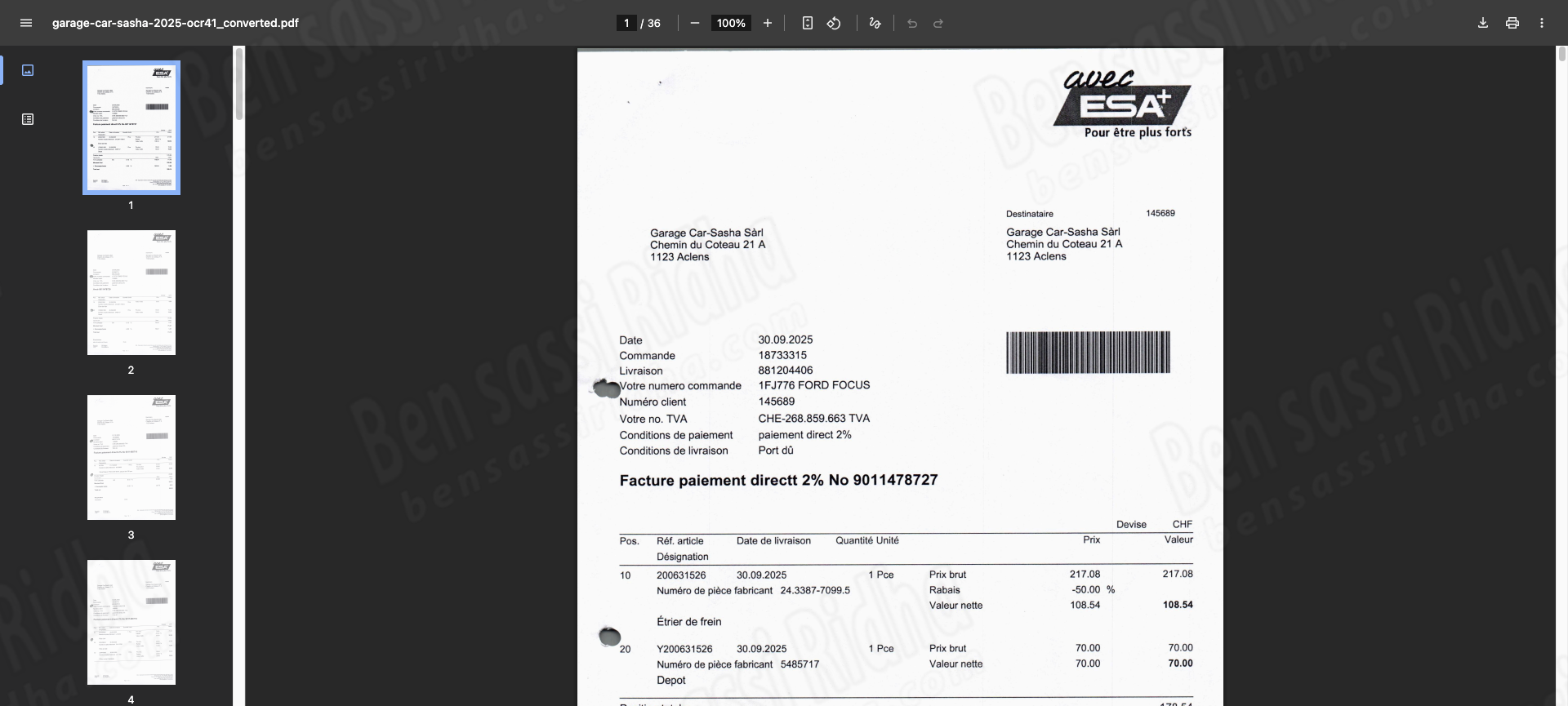
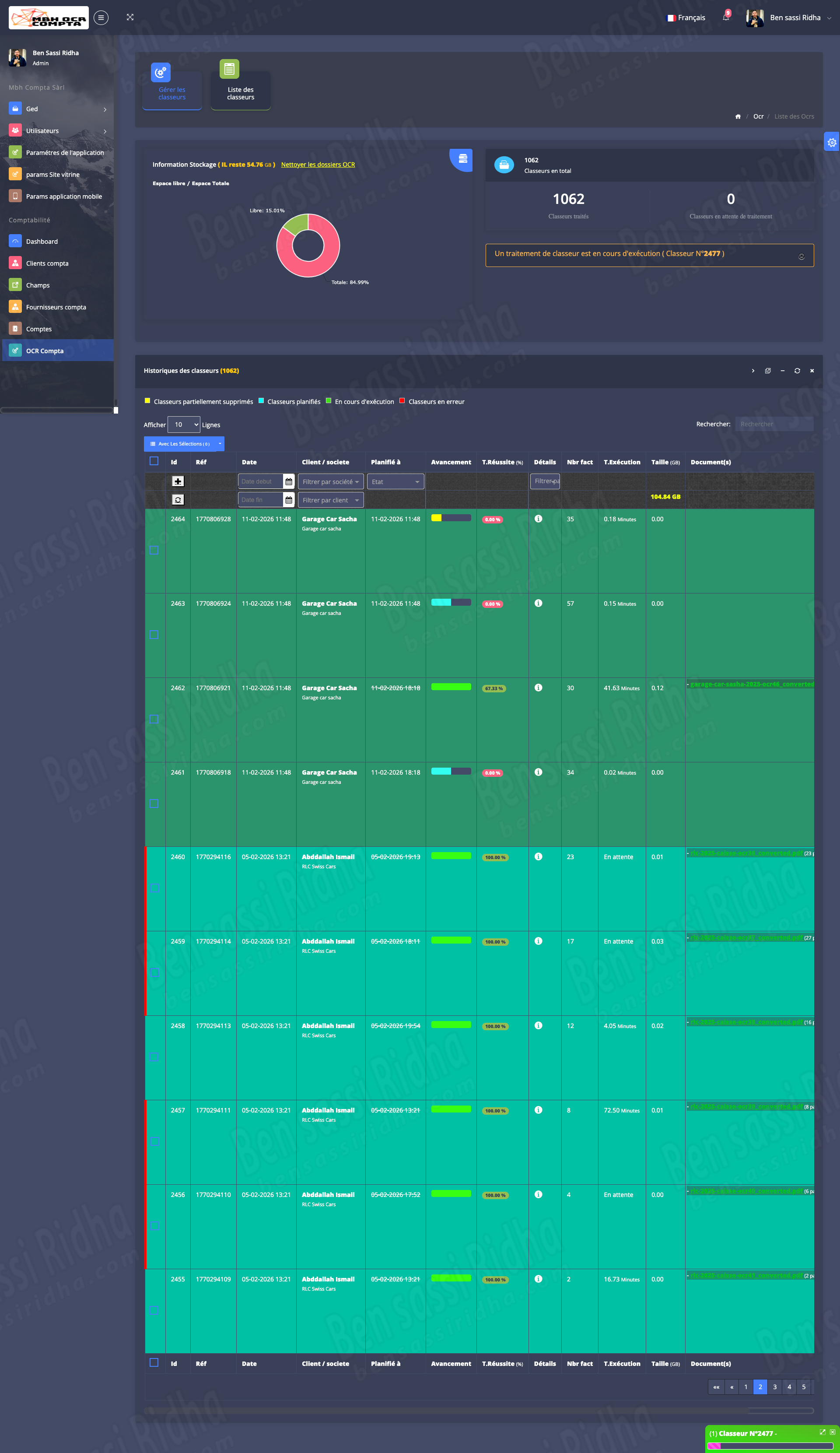
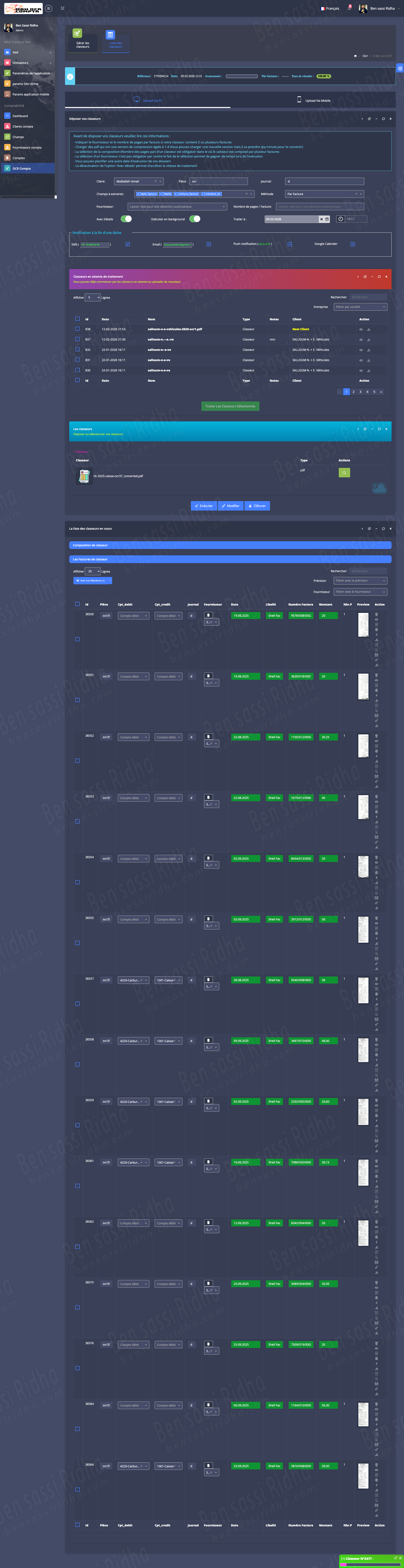
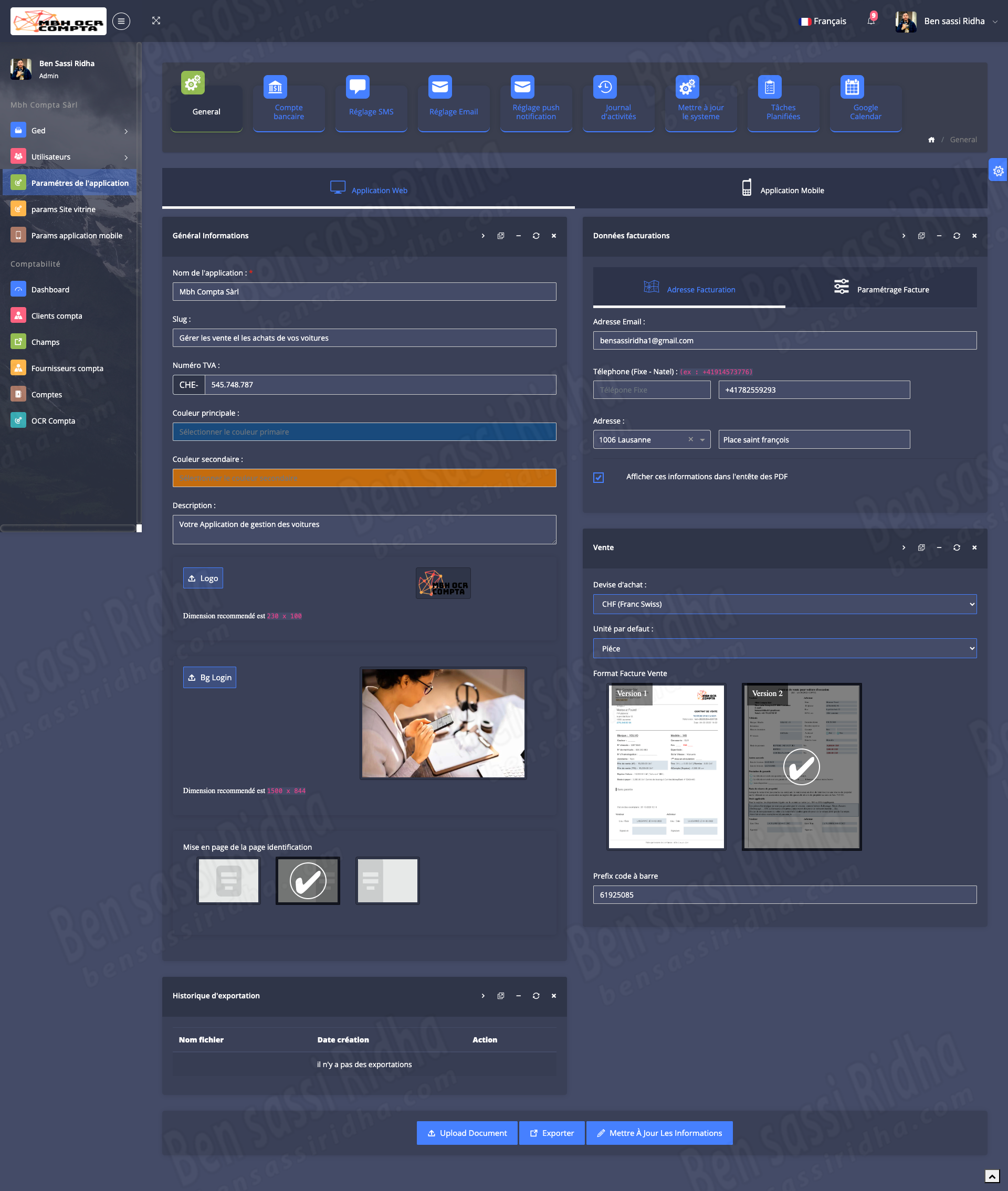
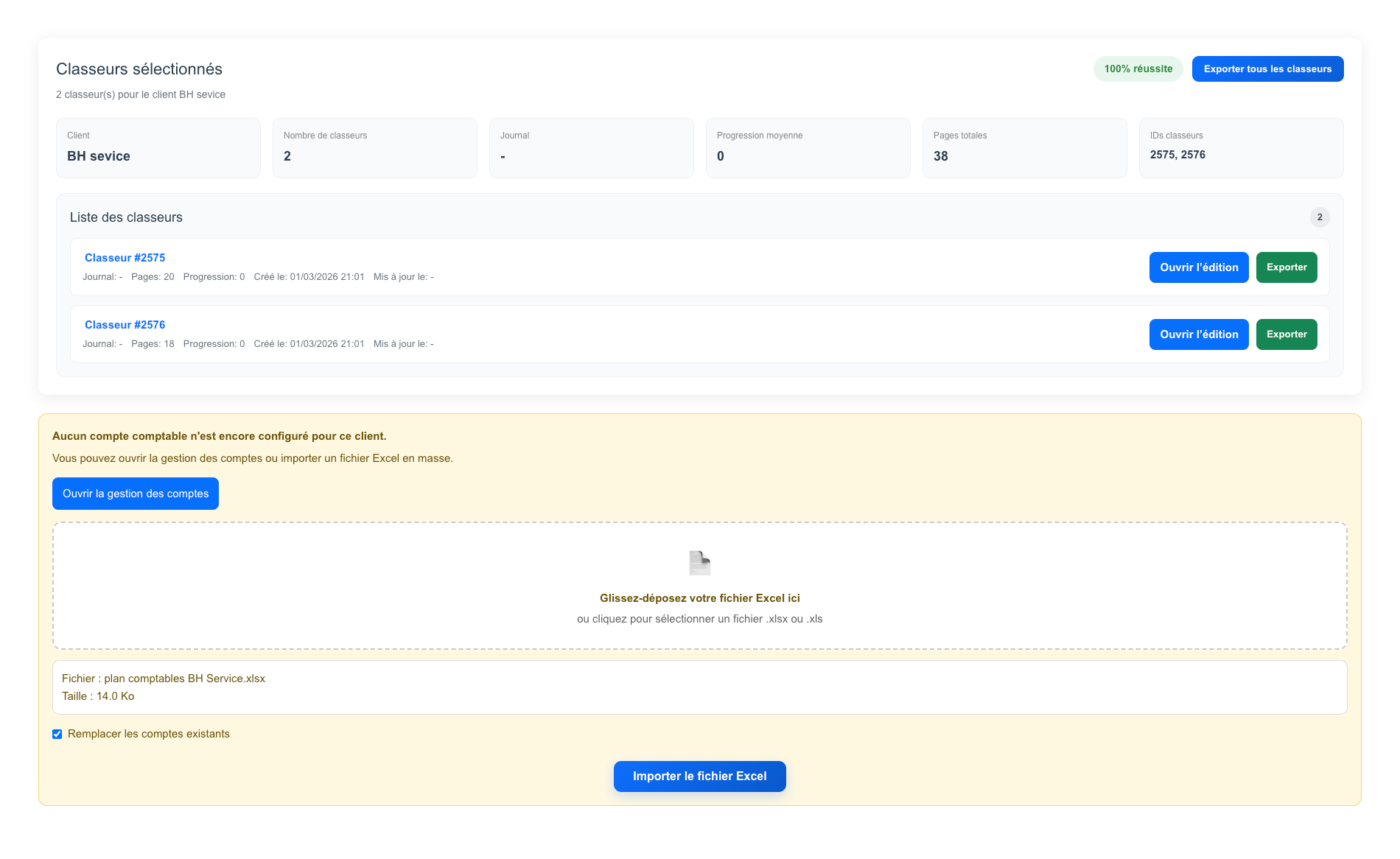
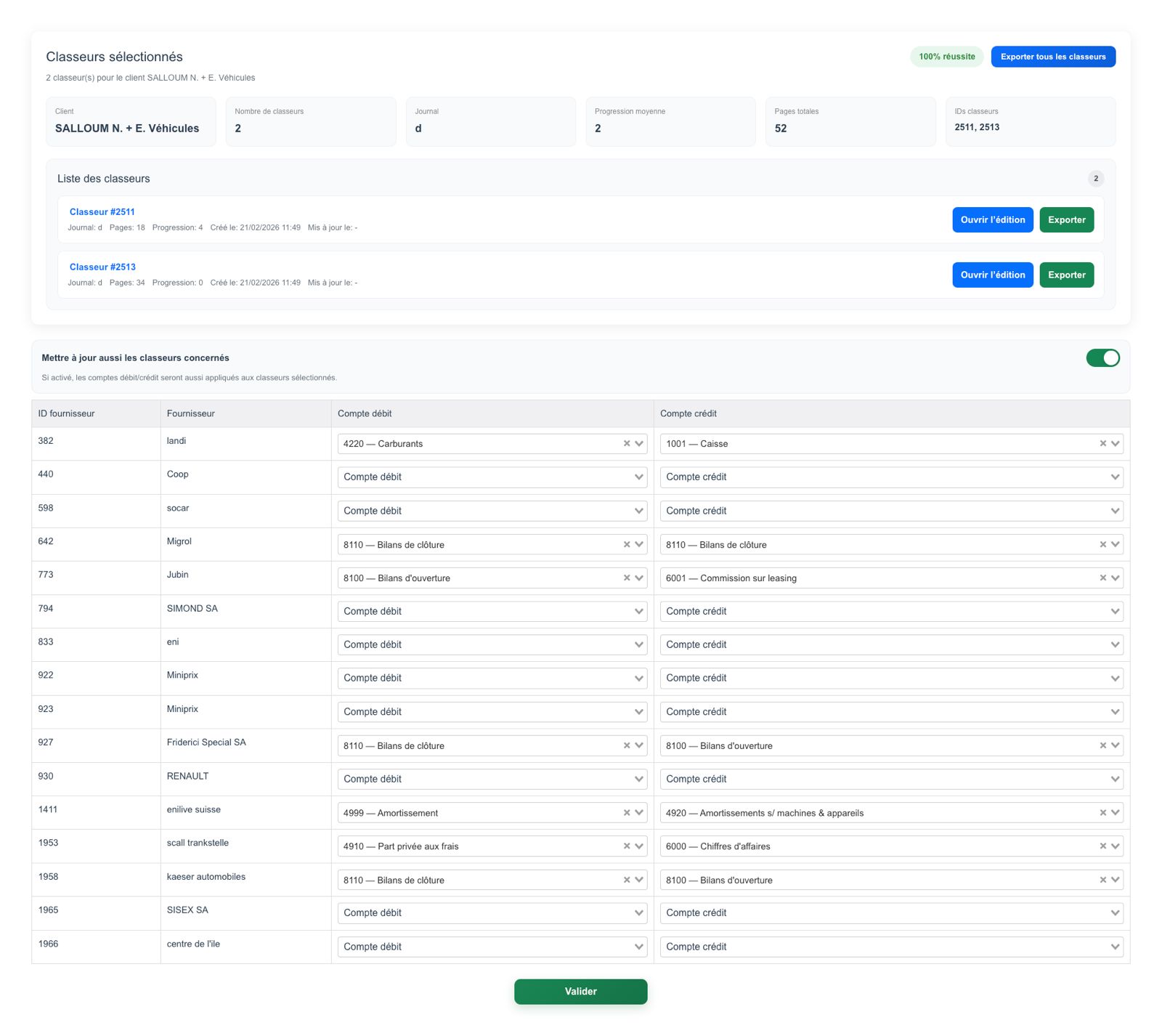
OCR COMPTA : Extraction of invoice data
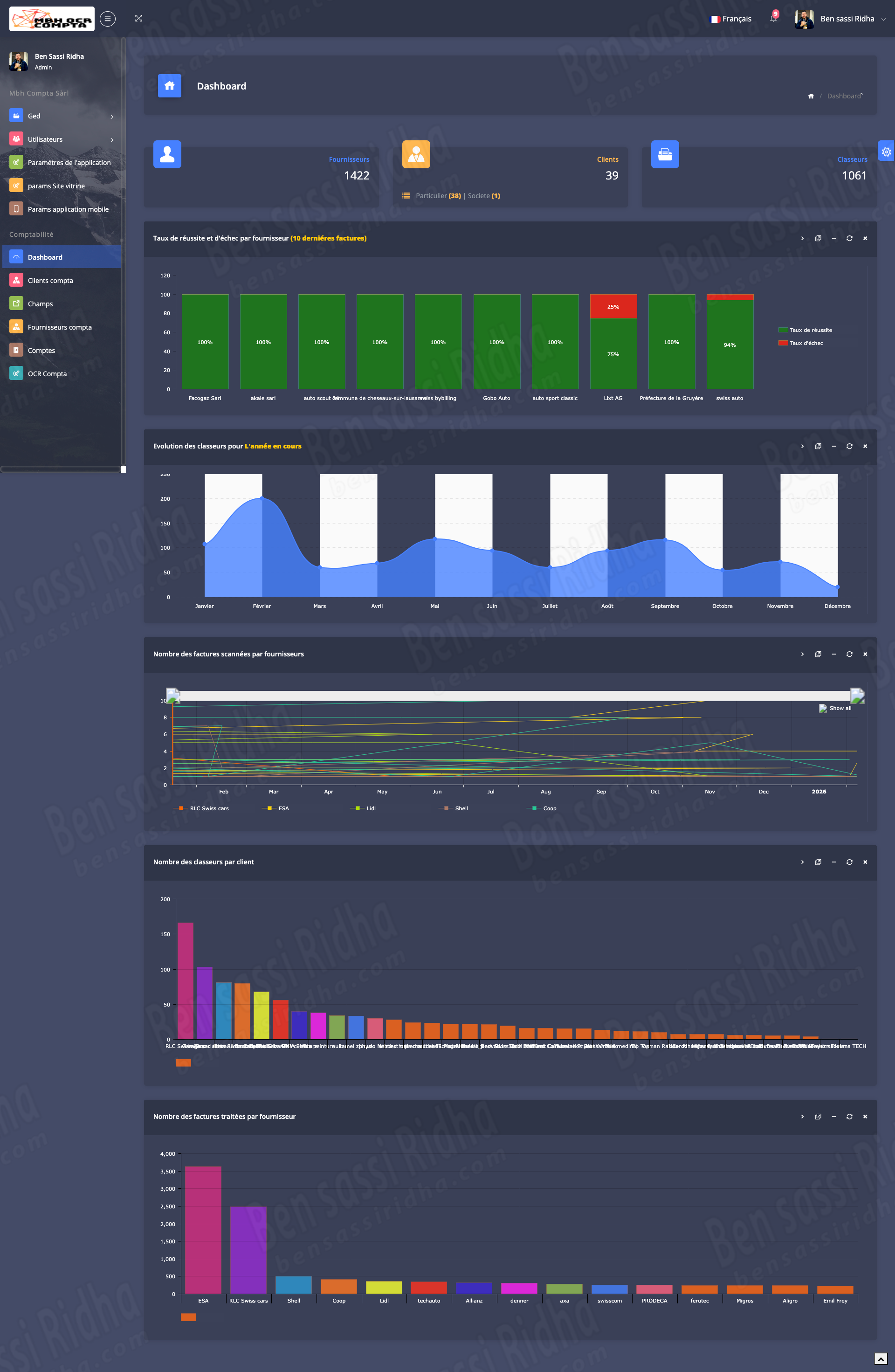
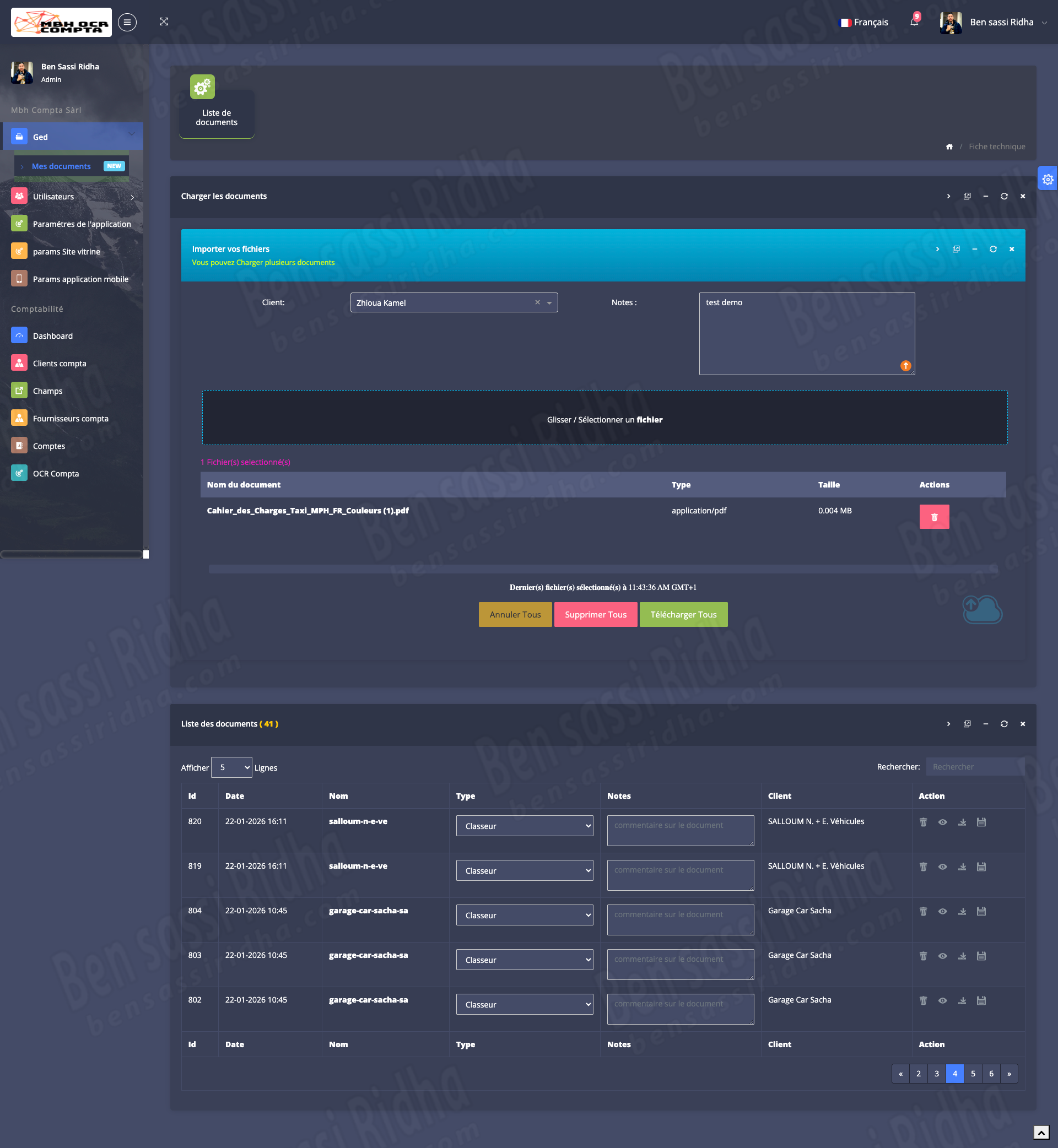
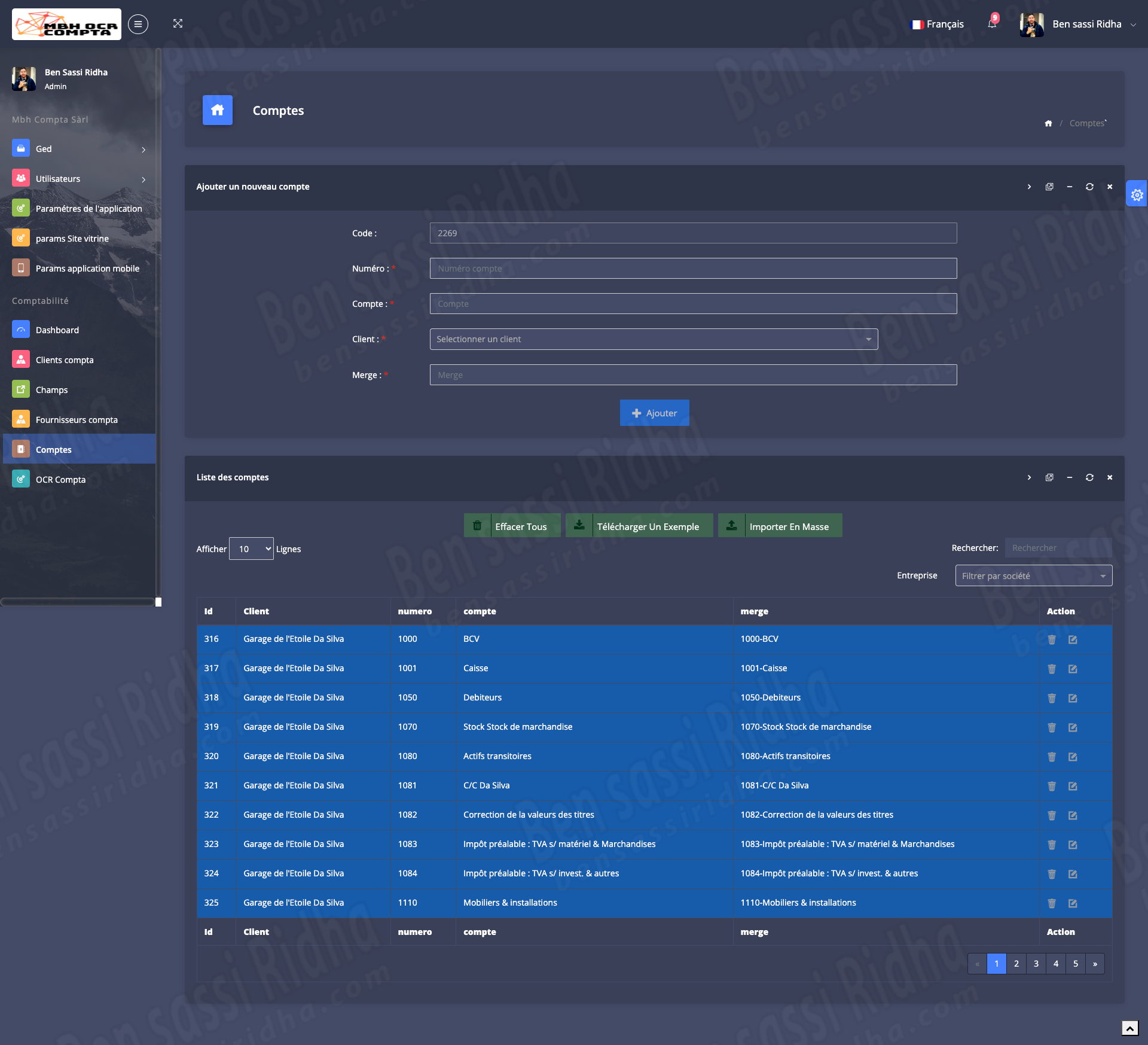
MBH OCR is an intelligent document processing solution that automatically extracts accounting data from scanned documents, invoices, and workbooks, streamlining financial workflows and improving accuracy.
- Client Several clients
- Date 15 June 2022
- Services Web Application
- Budget $10 000+
- Duration 2 Years

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}